Efficiently loading inlined JSON data
Quip's web site is client-side rendered using React. We normally load data over HTTP using our syncer architecture, but to avoid the extra roundtrip for the first screen that's displayed, we embed it into the initial HTML response. Once the server has loaded the data that the client will need¹, it outputs it using a simple <script> tag of the form:
<script>
app.desktop.main([JSON data]);
</script>
This is a very common pattern, and many client-side apps (going back to Gmail) use this approach. In Quip's case the JSON data can range from small (for an “Updates” screen permalink in a small account) to rather large (hundreds of kilobytes for a large document screen in an account with lots of contacts).
At some point last fall Belinda approached me about debugging a performance problem when loading large spreadsheets. While doing some profiling, we were surprised by both the memory use and the large amount of time spent building the JavaScript AST. After thinking about it for a bit, I realized that this made sense: the browser was parsing the <script> tag as arbitrary JavaScript. It had no way of knowing that the [JSON data] subtree was entirely JSON and thus could be parsed directly into a simple data structure with a much more efficient parser.
This reminded me of the difference between using eval and JSON.parse to parse JSON data in network responses. Though tricky to benchmark, it is indeed the case that JSON.parse is quite a bit faster because it has to do a lot less work. I wondered if I could apply the same approach to the data that we're embedding in our HTML. I came up with this split between code and data (inlined here for the sake of brevity):
<script type="application/json">
[JSON data]
</script>
<script>
const jsonNode = document.querySelector("script[type='application/json']");
const jsonText = jsonNode.textContent;
const jsonData = JSON.parse(jsonData);
app.desktop.main(jsonData);
</script>
By giving the JSON data a non-standard type in the <script> tag, the browser won't try to parse it as JavaScript (it'll be treated as an ”inert” data block). We can then get the raw text and parse it more efficiently using JSON.parse.
For my Quip account loading a large document (the HTML response is 550K) this takes the end-to-end (navigation-to-render) time from 1,830ms to 1,758ms based on some simple benchmarking. Though not a huge gain, it is noticeable and did not require almost any added complexity.
To measure the impact of this approach in more controlled circumstances, I created a simple test bed (source). It tests the end-to-end loading time using both approaches using different data sizes² on various platforms³:
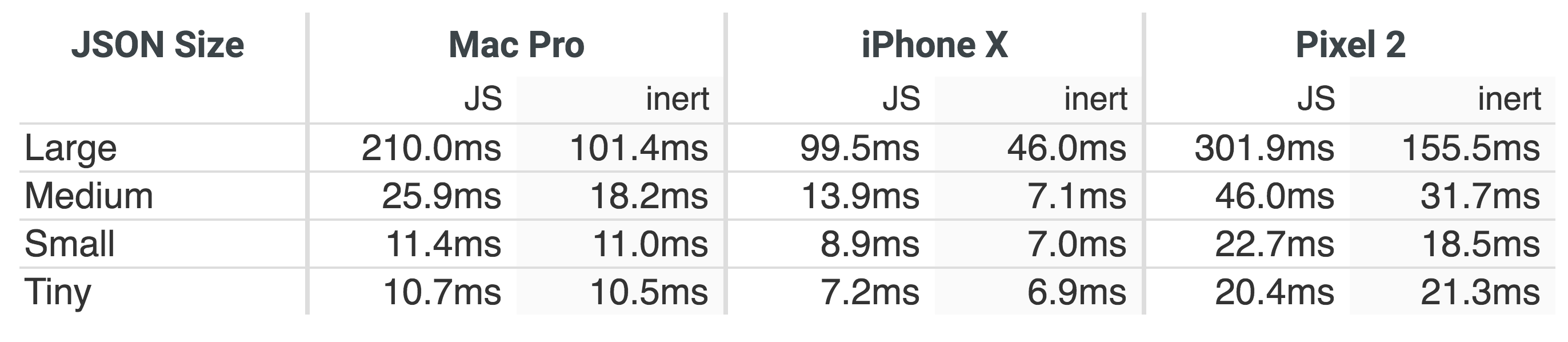
The larger the JSON size, the larger the benefit. Additionally, making the JSON into an “inert” script benefits CPU constrained mobile platforms more.
One interesting discovery that I made while working on this benchmark was that WebKit has code that tries to detect this pattern. My initial harness was giving identical results with both the JS and the “inert” approaches on my iPhone. Only when I added a no-op function call to the JS snippet did I get the expected performance difference. My best guess is that the JSONP detector was kicking in, since the <script> consisted solely of a function call with a JSON parameter. In reality Quip's embedded JSON data is in a more complex <script>, so making the benchmark simulate that complexity seemed appropriate.
All of this has been in the context of Quip's web app, but our hybrid desktop app can also benefit from this split of data and code. On the Mac we use a WebView that is given data using stringByEvaluatingJavaScriptFromString. The parameter is the form of a platform.native.handleReponse([JSON data]) function call, which looks very similar to the HTML snippet that we started with. If we could instead load the JSON data more directly, the JavaScript that gets evaluated would consist of the code only. Luckily, we can access the JavaScript context of a WebView using public APIs, and there we can use JSValueMakeFromJSONString to efficiently load the JSON data.
Putting it all together, this results in:
// Some way to get the JSON as a JSStringRef
JSStringRef pbLiteArgJsString = ...;
// Parse the JSON string as JSON using the JavaScriptCore API that bypasses
// traditional JS parsing.
JSContextRef jsContext = webView.mainFrame.globalContext;
JSValueRef pbLiteArgJsValue = JSValueMakeFromJSONString(jsContext, pbLiteArgJsString);
// Release the string version of the JSON data as soon as possible, to minimize
// the peak memory use.
JSStringRelease(pbLiteArgJsString);
// Make the JSON data available as a generatedPbLiteArg_N global variable
static int pbLiteArgNameCounter = 0;
NSString *pbLiteArgName = [NSString stringWithFormat:@"generatedPbLiteArg_%d", pbLiteArgNameCounter++];
JSStringRef pbLiteArgNameJsString = JSStringCreateWithCFString((__bridge CFStringRef) pbLiteArgName);
JSObjectSetProperty(jsContext, JSContextGetGlobalObject(jsContext), pbLiteArgNameJsString, pbLiteArgJsValue, kJSPropertyAttributeNone, NULL);
JSStringRelease(pbLiteArgNameJsString);
// Generate the function call that uses the generatedPbLiteArg_N global variable
// as the parameter name. It then deletes the reference as soon as the code runs,
// to avoid leaking memory.
NSString *js = [NSString stringWithFormat:@"platform.native.handleReponse(%@); delete %@;",pbLiteArgName, pbLiteArgName];
[webView stringByEvaluatingJavaScriptFromString:js];
In my testing with a large spreadsheet (~20,000 cells) in our Mac app, this took the time for the data load from 1,014ms to 533ms and the peak memory use from 783MB to 603MB. On iOS we still use UIWebView, and though there is no officially documented way to get the JavaScript context, there are workarounds, and they should be compatible with this method too.
This split between data and code reminds me of the Harvard architecture, so let no one tell you that mid-1940s computer architecture has no bearing on modern web development.
- While the server is doing this load the initial part of the HTML response (containing the
<link>tag for our stylesheet and<script src="...">for our JavaScript) is flushed, so that the browser can download and parse them in parallel with the data fetch and transfer. - The data sizes are as follows: large is 1.7MB of JSON, medium is 130K, small is 10K and tiny is 781 bytes. The JSON data is meant to resemble JsPbLite since that's what Quip happens to use as a serialization system. The JSON is part of a scaffolding HTML document that is loaded in an iframe (via a blob URL) which then reports to the parent when it has parsed the input.
- Mac Pro: Chrome 65.0.3311.3 on 2010 Mac Pro (12 core) running macOS 10.12.6
iPhone X: Safari on iPhone X running iOS 11.2.1
Pixel 2: Chrome 63.0.3239.111 on Pixel 2 running Android 8.1.0 (thanks to Akshay; Neil provided numbers for a Nexus 6P and the speedup was of similar magnitude)
